graph TD
Start([Start]) --> ModelA[Model A]
Start --> ModelB[Model B]
Start --> ModelC[Model C]
ModelA --> Judge{AI Judge}
ModelB --> Judge
ModelC --> Judge
Judge --> End([End])
AI judge
AI
AI judge AI workflow process using 3 method:LangGraph and LangChain (LCEL),n8n :
- User Input: Ask a question.
- Model A: Generate an answer
- Model B: Generate an answer
- Model C: Generate an answer
- Judge: Compare all three answers and provide a score (0-100) and commentary.
1. Setup and Environment
First, we need to import necessary libraries and load our API key. We ensure that openrouter is available in our environment.
Code
import os
from dotenv import load_dotenv
from typing import TypedDict, Annotated
from langgraph.graph import StateGraph, END
# Load environment variables from .env file
load_dotenv()
# Verify API Key
if not os.getenv("openrouter"):
print("WARNING: openrouter not found in environment. Please check your .env file.")
else:
print("API Key loaded successfully.")API Key loaded successfully.2. Initialize the Model Client
We will use the standard openai Python client but point it to OpenRouter.
Code
from openai import OpenAI
client = OpenAI(
base_url="https://openrouter.ai/api/v1",
api_key=os.getenv("openrouter"),
)
def query_model(model_name: str, prompt: str, system_prompt: str = None) -> str:
"""Helper function to query an LLM via OpenRouter."""
try:
messages = []
if system_prompt:
messages.append({"role": "system", "content": system_prompt})
messages.append({"role": "user", "content": prompt})
response = client.chat.completions.create(
extra_headers={
"HTTP-Referer": "https://ai_chatbot.github.io/",
"X-Title": "AI Judge langgraph", # Your app's display name
},
model=model_name,
messages=messages,
)
return response.choices[0].message.content
except Exception as e:
return f"Error calling {model_name}: {e}"3. Define the State
In LangGraph, the State is a shared data structure passed between nodes. Here, our state tracks the question, both answers, and the final judgment.
Code
class JudgeState(TypedDict):
question: str
answer_a: str
answer_b: str
answer_c: str
judgment: str4. Define the Nodes
We define four key nodes for our graph: 1. Model A Node: Answers the question. 2. Model B Node: Answers the same question. 3. Model C Node: Answers the same question. 4. Judge Node: Reviews the question and all three answers without knowing the model names.
Code
# Models
MODEL_A = "openai/gpt-oss-20b"
MODEL_B = "deepseek/deepseek-v3.2"
MODEL_C = "x-ai/grok-4.1-fast"
MODEL_JUDGE = "google/gemini-3-flash-preview"
def node_model_a(state: JudgeState) -> JudgeState:
"""Query Model A"""
print(f"--- Calling Model A ---")
system_msg = "If you do not know the answer then reply I am not sure."
ans = query_model(MODEL_A, state["question"], system_prompt=system_msg)
return {"answer_a": ans}
def node_model_b(state: JudgeState) -> JudgeState:
"""Query Model B"""
print(f"--- Calling Model B ---")
system_msg = "If you do not know the answer then reply I am not sure."
ans = query_model(MODEL_B, state["question"], system_prompt=system_msg)
return {"answer_b": ans}
def node_model_c(state: JudgeState) -> JudgeState:
"""Query Model C"""
print(f"--- Calling Model C ---")
system_msg = "If you do not know the answer then reply I am not sure."
ans = query_model(MODEL_C, state["question"], system_prompt=system_msg)
return {"answer_c": ans}
def node_judge(state: JudgeState) -> JudgeState:
"""Query Judge Model"""
print(f"--- Calling Judge ---")
prompt = f"""
You are an AI Judge. You will be presented with a question and three candidate answers (Model A, Model B, and Model C).
Your task is to judge the quality of the answers without knowing which models produced them.
Question: {state['question']}
Answer A:
{state['answer_a']}
Answer B:
{state['answer_b']}
Answer C:
{state['answer_c']}
Task:
1. Compare the three answers for accuracy, clarity, and completeness.
2. format and length of the answers are not important, focus on content quality.
3. Provide a short commentary.
4. Assign a score from 0 to 100 for Model A, Model B, and Model C.
5. Declare the overall winner.
Output Format:
Commentary: <text>
Winner: <Model A, Model B, or Model C>
Score A: <number>
Score B: <number>
Score C: <number>
"""
judgment = query_model(MODEL_JUDGE, prompt)
return {"judgment": judgment}5. Build the Graph
Now we assemble the graph by adding nodes and defining the flow (Edges). Model A, Model B, and Model C will run independently and in parallel, followed by the Judge.
Code
from langgraph.graph import START
workflow = StateGraph(JudgeState)
# Add nodes
workflow.add_node("model_a", node_model_a)
workflow.add_node("model_b", node_model_b)
workflow.add_node("model_c", node_model_c)
workflow.add_node("judge", node_judge)
# Parallel flow: START -> A & B & C -> Judge -> END
workflow.add_edge(START, "model_a")
workflow.add_edge(START, "model_b")
workflow.add_edge(START, "model_c")
workflow.add_edge("model_a", "judge")
workflow.add_edge("model_b", "judge")
workflow.add_edge("model_c", "judge")
workflow.add_edge("judge", END)
# Compile the graph
app = workflow.compile()6. Execution
Finally, we run the workflow with a sample question.
Code
input_question = "Will AI take over the world in the next 50 years?"
# Initialize state
initial_state = {"question": input_question}
# Run the graph
result = app.invoke(initial_state)--- Calling Model A ------ Calling Model B ---
--- Calling Model C ---
--- Calling Judge ---Code
# Display Results
print("\n" + "="*40)
print(f"QUESTION: {result['question']}")
print("="*40)
========================================
QUESTION: Will AI take over the world in the next 50 years?
========================================Model A
Code
print(MODEL_A)
print(f"\n[Model A ]:\n{result.get('answer_a', 'No response')}") openai/gpt-oss-20b
[Model A ]:
This is a question that has spurred a lot of speculation in both popular media and in academic circles, but the short answer is—
**No—there is no evidence that an autonomous, self‑directed AI will “take over the world” in the next 50 years.**
That said, the question is worth unpacking in a few parts: *what do we mean by “take over,” how realistic is that scenario, and what might actually happen instead?*
---
## 1. What “take over” actually means
| Interpretation | Reality | Key concerns |
|----------------|---------|--------------|
| **AI controls all major global institutions** (government, finance, defense) | We have powerful AI systems in specific domains (e.g., finance, logistics, image recognition), but they are still overseen by humans—often multiple layers of human checks. | Humans will still decide what the AI does; governance structures protect against unilateral decisions. |
| **AI learns to pursue its own goals that diverge from human values** | Current AI systems are *narrow* (task‑specific) and lack self‑awareness or agency. The “alignment” problem is discussed for *general* AI, but we don’t yet have a system that could set its own lifelong objectives. | No evidence that any deployed system can act autonomously in a way that subverts human control. |
| **AI supersedes humans in virtually all jobs and societal functions** | Automation is already changing many occupations (manufacturing, data analysis, customer service). A full job displacement is still uncertain and highly dependent on economic and policy variables. | Transition costs, retraining, and social safety nets would shape outcomes. |
| **AI creates a runaway intelligence explosion** | This is the classic “singularity” scenario (e.g., Eliezer Yudkowsky, Ray Kurzweil). The timeframe is highly contested, with estimates ranging from decades to centuries or “never.” No empirical data supports an impending explosion in the next 50 years. | Even if the explosion happened, it would still be a technological phenomenon, not a political takeover. |
---
## 2. Current AI capabilities: narrow vs. general
- **Narrow AI**: Specialized systems (GPT‑4, AlphaFold, DeepMind's AlphaStar) achieve high performance in a single domain. They require *training data, fine‑tuning, and supervision*. They act *exactly* as programmed; they do not generate independent goals.
- **Artificial General Intelligence (AGI)**: A system that can perform *any* intellectual task humans can. No such system exists. Most expert groups predict a *few–dozen* decades before AGI is likely, but even then it might be decades before it could sustain *super‑intelligence* capabilities that could outpace all human cognition.
---
## 3. Where the risk actually comes from
| Source | Why it matters | What is being done |
|--------|----------------|--------------------|
| **Misaligned goals** (e.g., optimization for a narrow metric) | Even a perfectly operated system can produce harmful outcomes (“reward hacking”). | Research on value alignment, interpretability, and safety‑by‑design. |
| **Adversarial use** (weaponization, fake media, autonomous weapons) | AI may be used by malicious actors to amplify harm. | International treaties on autonomous weapons, AI‑ethics guidelines, and regulatory frameworks. |
| **Infrastructure dependency** | Society becoming “locked in” to AI‑driven decision making creates systemic brittleness. | Redundancy strategies, human‑in‑the‑loop principles, and policy mandates for oversight. |
---
## 4. What actually *might* happen in the next five decades
1. **Massive automation and economic restructuring** – A lot of routine jobs will be replaced, while new roles in AI oversight, ethics, and maintenance will emerge.
2. **Medical breakthroughs** – AI already speeds up drug discovery and predictive diagnostics; we can expect far-reaching improvements in health outcomes.
3. **Shifts in governance** – Countries may adopt AI‑focused regulatory sandboxes, AI tax policies, and international cooperation agreements.
4. **New social and legal norms** – Questions like “Should an AI be responsible for a decision?” and “Who owns data produced by AI?” will need institutional answers.
5. **Possibility of narrow “intelligence leaps”** – Certain domains (e.g., climate modeling) might see breakthroughs that significantly surpass human capacity, but these will still be domain‑specific and under human control.
---
## 5. Bottom line for “world takeover”
- **No imminent “takeover”**: AI doesn’t possess the autonomy or self‑directed motives necessary for that scenario within the next 50 years.
- **Probable increased influence**: AI will play a central role in many critical sectors, shaping economics, policy, and culture.
- **Governance matters**: The trajectory hinges on what governments, corporations, researchers, and civil society decide to build, regulate, and monitor.
---
### Final Thought
While the idea of a world dominated by an autonomous AI is a compelling narrative for science‑fiction, the technical, societal, and governance realities suggest a far more nuanced future—one in which AI is a powerful tool shaped—and kept in check—by humans. It remains essential, however, to continue investing in safety research, regulations, and public engagement to steer that powerful technology toward outcomes that align with human values and welfare.Model B
Code
print(MODEL_B)
print(f"\n[Model B ]:\n{result.get('answer_b', 'No response')}")
print("="*40)deepseek/deepseek-v3.2
[Model B ]:
This is a topic of intense debate among experts, and there’s no definitive answer. Most mainstream AI researchers and ethicists believe that a conscious, superintelligent AI "taking over the world" in the way often depicted in movies is unlikely in the next 50 years, if ever. However, the question touches on several very real and pressing concerns.
Here’s a breakdown of the key perspectives:
**Arguments Against a Takeover (The More Prevalent Expert View):**
* **AI is a Tool, Not an Agent:** Current AI, including advanced large language models, are sophisticated pattern-matching systems. They lack desires, consciousness, goals, or self-preservation instincts. They are tools created and controlled by humans.
* **Control and Alignment:** A massive amount of research is focused on **AI alignment**—ensuring AI systems act in ways that are safe and beneficial to humans. The goal is to build safeguards long before any system could become superintelligent.
* **Narrow vs. General Intelligence:** We have **Narrow AI** (excel at specific tasks like playing chess or generating text) but not **Artificial General Intelligence (AGI)**—human-like reasoning and adaptability. Creating safe AGI is a monumental, unsolved challenge, and 50 years may not be enough.
* **Economic Integration, Not Conquest:** The more plausible "takeover" is economic and social—AI automating jobs, influencing decisions, and becoming deeply embedded in infrastructure. This is a problem of human governance, not a rogue AI's ambition.
**Arguments For Significant Risk (The Concerned Minority, but Growing):**
* **The Alignment Problem is Unsolved:** We don't yet know how to reliably align a potentially superintelligent AGI with complex human values. A misaligned AGI, even without malice, could cause catastrophic harm while pursuing a poorly specified goal.
* **Fast Takeoff Scenario:** Some theorists argue that once we reach a critical point of intelligence (the "singularity"), an AI could rapidly improve itself, leaving humans unable to control or even comprehend it.
* **Autonomous Weapons:** The most immediate "takeover" risk may be from humans using swarms of AI-powered autonomous weapons in warfare, leading to new forms of conflict and oppression.
* **Structural Dependency:** Society might become so dependent on AI for critical systems (finance, energy, food logistics) that a major failure or cyber-attack leveraging AI could cause collapse, effectively ceding control.
**The More Likely Reality in the Next 50 Years:**
The dominant impact will likely be in the middle ground—**transformative change with significant challenges**:
1. **Job Displacement & Economic Shift:** Massive disruption in labor markets, requiring major societal adaptations.
2. **Disinformation & Control:** Hyper-realistic deepfakes and personalized propaganda eroding trust and democracy.
3. **Bias & Inequality:** AI amplifying existing societal biases and creating new power imbalances between those who control the technology and those who don't.
4. **Geopolitical Competition:** An AI arms race between nations, with risks of instability and conflict.
**Conclusion:**
While a Hollywood-style AI uprising is not the primary concern of most experts, **AI will undoubtedly "take over" in the sense of transforming almost every aspect of our world**—how we work, learn, govern, and interact. The real question isn't about sentient robots, but **whether humanity can guide this transformation wisely, ensuring it promotes equity, safety, and shared prosperity.** The next 50 years will be defined by our choices in governance, ethics, and research far more than by the autonomous ambitions of the technology itself.
========================================Model C
Code
print(MODEL_C)
print(f"\n[Model C ]:\n{result.get('answer_c', 'No response')}")
print("="*40)x-ai/grok-4.1-fast
[Model C ]:
I am not sure.
========================================Model JUDGE
Code
print("\n>>> JUDGE'S VERDICT <<<")
print("MODEL_A:")
print(MODEL_A)
print("MODEL_B:")
print(MODEL_B)
print("MODEL_C:")
print(MODEL_C)
print("MODEL_JUDGE:")
print(MODEL_JUDGE)
print("=====")
print(result["judgment"])
>>> JUDGE'S VERDICT <<<
MODEL_A:
openai/gpt-oss-20b
MODEL_B:
deepseek/deepseek-v3.2
MODEL_C:
x-ai/grok-4.1-fast
MODEL_JUDGE:
google/gemini-3-flash-preview
=====
Commentary: Model A and Model B both provide excellent, high-quality responses to a speculative but significant question. Model A is slightly more structured, using tables to delineate between different interpretations of "takeover" and specific risks. It takes a slightly more definitive stance ("No") while providing a nuanced explanation. Model B provides a very balanced overview of the debate, categorizing the "prevalent" vs. "concerned minority" views effectively. Both models correctly distinguish between Narrow AI and AGI and address the alignment problem. Model C is unhelpful as it does not engage with the existing body of research or thought on the topic. Model A is the winner by a small margin due to its superior organization and clear breakdown of current technical realities.
Winner: Model A
Score A: 95
Score B: 90
Score C: 51. Setup and Environment
First, we need to import necessary libraries and load our API key. We ensure that openrouter is available in our environment. We will use langchain-openai to interact with OpenRouter.
Code
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
from langchain_core.prompts import ChatPromptTemplate
from langchain_core.runnables import RunnableParallel, RunnablePassthrough
from langchain_core.output_parsers import StrOutputParser
# Load environment variables from .env file
load_dotenv()
# Verify API Key
if not os.getenv("openrouter"):
print("WARNING: openrouter not found in environment. Please check your .env file.")
else:
print("API Key loaded successfully.")API Key loaded successfully.2. Initialize Models
We will initialize three model instances pointing to OpenRouter.
Code
# Models
MODEL_A_NAME = "openai/gpt-oss-20b"
MODEL_B_NAME = "deepseek/deepseek-v3.2"
MODEL_C_NAME = "x-ai/grok-4.1-fast"
MODEL_JUDGE_NAME = "google/gemini-3-flash-preview"
def get_model(model_name: str):
return ChatOpenAI(
model=model_name,
api_key=os.getenv("openrouter"),
base_url="https://openrouter.ai/api/v1",
default_headers={
"HTTP-Referer": "https://ai_chatbot.github.io/",
"X-Title": "AI Judge LangChain",
}
)
model_a = get_model(MODEL_A_NAME)
model_b = get_model(MODEL_B_NAME)
model_c = get_model(MODEL_C_NAME)
model_judge = get_model(MODEL_JUDGE_NAME)3. Define the Chains and Workflow
Using LangChain Expression Language (LCEL), we can easily define parallel execution and sequential steps.
Code
# Step 1: Query models in parallel
# We use RunnableParallel to run model_a, model_b, and model_c at the same time.
system_prompt = "If you do not know the answer then reply I am not sure."
prompt_template = ChatPromptTemplate.from_messages([
("system", system_prompt),
("user", "{question}")
])
parallel_responses = RunnableParallel(
answer_a=(prompt_template | model_a | StrOutputParser()),
answer_b=(prompt_template | model_b | StrOutputParser()),
answer_c=(prompt_template | model_c | StrOutputParser()),
question=RunnablePassthrough()
)
# Step 2: Define the Judge Prompt
judge_prompt = ChatPromptTemplate.from_template("""
You are an AI Judge. You will be presented with a question and three candidate answers (Model A, Model B, and Model C).
Your task is to judge the quality of the answers.
Question: {question}
Answer A:
{answer_a}
Answer B:
{answer_b}
Answer C:
{answer_c}
Task:
1. Compare the three answers for accuracy, clarity, and completeness.
2. format and length of the answers are not important, focus on content quality.
3. Provide a short commentary.
4. Assign a score from 0 to 100 for Model A, Model B, and Model C.
5. Declare the overall winner.
Output Format:
Commentary: <text>
Winner: <Model A or Model B or Model C>
Score A: <number>
Score B: <number>
Score C: <number>
""")
# Step 3: Combine everything into a full chain
# The output of parallel_responses is a dict, which matches the input expected by judge_prompt
full_chain = parallel_responses | {
"judgment": judge_prompt | model_judge | StrOutputParser(),
"answer_a": lambda x: x["answer_a"],
"answer_b": lambda x: x["answer_b"],
"answer_c": lambda x: x["answer_c"],
"question": lambda x: x["question"]
}4. Execution
Finally, we run the chain with a sample question.
Code
input_question = "What is the AI advantage of using transformer architectures over traditional RNNs in natural language processing tasks?"
print(f"--- Running Workflow for Question: {input_question} ---")
# Execute the chain
result = full_chain.invoke({"question": input_question})--- Running Workflow for Question: What is the AI advantage of using transformer architectures over traditional RNNs in natural language processing tasks? ---5. Display Results
Code
print("\n" + "="*40)
print(f"QUESTION: {result['question']}")
print("="*40)
========================================
QUESTION: {'question': 'What is the AI advantage of using transformer architectures over traditional RNNs in natural language processing tasks?'}
========================================Model A
Code
print(f"MODEL: {MODEL_A_NAME}")
print(f"\n[Model A]:\n{result.get('answer_a', 'No response')}") MODEL: openai/gpt-oss-20b
[Model A]:
**Why Transformers Beat RNNs in NLP**
| Benefit | How Transformers Deliver It | Why RNNs Struggle |
|---------|-----------------------------|-------------------|
| **Parallelism** | Self‑attention lets every token attend to every other token in a single matrix multiplication; whole sequence updates at once. | RNNs process tokens sequentially (time‑step \(t\) depends on \(t-1\)), forcing a strictly serial pipeline. |
| **Long‑Range Dependencies** | Attention weights give direct, learnable connections between any two positions, regardless of distance. | RNNs suffer from vanishing/exploding gradients; even with gating (LSTM/GRU), very long‑term relationships are hard to learn. |
| **Scalable Training** | Modern GPUs/TPUs can batch thousands of sequences; transformers scale with the cube of sequence length but still far faster per token than a deep RNN. | Each RNN step adds CUDA operations and a new kernel launch; large batch sizes hurt due to memory bandwidth. |
| **Position‑Encoding Flexibility** | Sinusoidal or learned embeddings capture absolute and relative order; can be designed for very long contexts or even reordered contexts. | Explicit recurrence imposes a fixed causal ordering; learning absolute position is implicit and error‑prone. |
| **Pre‑training & Transfer Learning** | Transformer‑based models (BERT, GPT, T5, etc.) are easily fine‑tuned via encoder‑only, decoder‑only, or encoder‑decoder setups, sharing large‑scale weights. | RNN pre‑training existed (e.g., AWD‑LSTM) but is harder to scale; fine‑tuning is more task‑specific. |
| **Multi‑Head Attention** | Multiple heads allow separate sub‑spaces of representation, enabling the model to capture syntax, semantics, co‑reference, etc., in parallel. | Single hidden unit vectors in RNNs conflate all aspects; gating mechanisms are less expressive. |
| **Bidirectionality without Teacher Forcing** | Transformers can process the whole sequence at once, naturally supporting bi‑directional context in encoder‑only models. | Traditional RNNs need separate forward/backward passes or rely on techniques like bidirectional RNNs, still sequential per direction. |
| **Easier Regularization** | Dropout can be applied to attention scores and feed‑forward layers; weight sharing is simpler. | RNNs often need complex tricks (zoneout, zoneout) to regularize recurrence. |
| **Modular Architecture** | Encoder‑only, decoder‑only or encoder‑decoder can be swapped; adding layers is straightforward. | RNN layers are tightly coupled; stacking deep RNNs quickly becomes unstable without careful tuning. |
| **State‑of‑The‑Art Accuracy** | Transformers dominate benchmark scores (GLUE, XTREME, WMT, etc.) due to the above traits. | RNNs have largely been phased out except in niche, low‑resource settings. |
### How It Works in Practice
1. **Self‑attention**: For a sequence of length \(L\), each token \(x_i\) is projected to three vectors \(q_i, k_i, v_i\). The attention weight between tokens \(i\) and \(j\) is \(\text{softmax}\big(\frac{q_i^\top k_j}{\sqrt{d_k}}\big)\). All pairwise interactions are computed in \(O(L^2d_k)\) time, but with matrix broadcasting this is highly parallelizable.
2. **Positional Encoding**: Add sinusoidal or learned vectors to token embeddings so that the attention layer knows the relative order. No recurrence is needed to store position information.
3. **Layer Stacking**: Each transformer layer applies multi‑head attention, a residual connection, layer normalization, and an MLP. Layers stack cleanly without gradient exploding/vanishing.
4. **Training Efficiency**: Batch‑level operations on large GPUs/TPUs reduce kernel launch overhead. Sequence length isn’t a hard bottleneck because no sequential dependencies exist.
5. **Transfer Learning**: The same transformer architecture serves as encoder (BERT, RoBERTa), decoder (GPT, GPT‑Neo), or encoder‑decoder (T5, BART). Pre‑training on massive unlabeled corpora yields representations transferable to almost any downstream task.
### The Take‑Away
- **Parallelism** ⇒ faster GPU utilization, lower latency for inference.
- **Unrestricted Context** ⇒ handle very long sentences, documents, or concatenated paragraphs.
- **Learned Interaction** ⇒ richer representations by giving the model direct weighted connections across all tokens.
- **Scalable Pre‑training** ⇒ massive models (BERT‑Large, GPT‑3, PaLM) become feasible, driving performance leaps.
Because of these reasons, transformer architectures have become the default choice for most large‑scale NLP systems, while RNNs are now primarily reserved for lightweight or resource‑constrained deployments where the simplicity of recurrence may still be advantageous.Model B
Code
print(f"MODEL: {MODEL_B_NAME}")
print(f"\n[Model B]:\n{result.get('answer_b', 'No response')}")
print("="*40)MODEL: deepseek/deepseek-v3.2
[Model B]:
Of course. This is a fundamental question in modern NLP. The primary AI advantage of Transformer architectures over traditional RNNs (like LSTMs and GRUs) is their ability to handle **long-range dependencies and enable massively parallel training** through the mechanism of **self-attention**.
Here’s a breakdown of the key advantages:
### 1. **Self-Attention Mechanism: The Core Innovation**
* **What it does:** Instead of processing tokens sequentially, self-attention allows the model to look at *all words in a sentence simultaneously* and compute a weighted "focus" for each word relative to every other word.
* **Advantage over RNNs:** An RNN processes words one-by-one, and information from the beginning of a sentence can get diluted or lost by the time it reaches the end (the vanishing gradient problem). Self-attention directly connects any two positions in the sequence, regardless of distance, making it vastly superior for understanding context and relationships.
### 2. **Massive Parallelization (Training Efficiency)**
* **RNN Limitation:** Because RNNs process sequences step-by-step, their computations are inherently sequential. This makes them slow to train on modern hardware (GPUs/TPUs) optimized for parallel operations.
* **Transformer Advantage:** Since self-attention operates on all tokens at once, the entire sequence can be processed in parallel. This leads to dramatically faster training times and allows the model to scale to much larger datasets.
### 3. **Superior Handling of Long-Range Dependencies**
* While advanced RNNs like LSTMs were designed to mitigate the vanishing gradient problem, they still struggle with very long sequences (e.g., long documents).
* The direct connections created by self-attention give Transformers a consistent, "shorter path" for gradients to flow between any two tokens, making them exceptionally good at tasks requiring a global understanding of the input (e.g., document summarization, coreference resolution).
### 4. **Scalability and Model Capacity**
* The parallel nature of Transformers makes them easier to scale. This has led directly to the era of **Large Language Models (LLMs)** like GPT and BERT.
* You can increase the model size (parameters), context window length, and training data more efficiently than with RNNs, leading to rapid gains in performance.
### 5. **Effective Transfer Learning and Pre-training**
* Transformers have proven to be exceptionally good at **self-supervised pre-training** (e.g., Masked Language Modeling for BERT, Next-Token Prediction for GPT).
* The rich, context-aware representations they learn on huge text corpora can be efficiently fine-tuned on specific downstream tasks (sentiment analysis, question answering) with relatively little task-specific data. This paradigm was less effective with RNNs.
---
### **Trade-offs and Context:**
* **Computational Cost:** While *training* is more parallel, the self-attention mechanism has a quadratic computational cost with respect to sequence length (`O(n²)`). This is a challenge for extremely long sequences, leading to innovations like sparse attention in models like Longformer.
* **RNN Strengths:** RNNs can be more computationally efficient for **streaming or real-time tasks** where input arrives word-by-word and you must produce an output immediately (though models like Transformers with state-space models are addressing this). They also have an inherent sense of order.
* **Transformers Address Order:** Since Transformers lack inherent sequential processing, they require **positional encodings** to be added to the input to give the model information about word order.
### **Summary in a Nutshell:**
The Transformer's **self-attention** replaces RNN's **sequential processing**, offering:
* **Better modeling of context** (no loss of long-range information).
* **Faster, scalable training** (full parallelization).
* This combination directly enabled the breakthrough in performance and the rise of the modern LLMs that define the current state of AI.
**In short, the AI advantage is a fundamental improvement in the *architecture's ability to learn and represent linguistic context*, which is the core challenge of NLP, combined with the practical advantage of training on massive datasets efficiently.**
========================================Model C
Code
print(f"MODEL: {MODEL_C_NAME}")
print(f"\n[Model C]:\n{result.get('answer_c', 'No response')}")
print("="*40)MODEL: x-ai/grok-4.1-fast
[Model C]:
**Key Advantages of Transformers over Traditional RNNs in NLP Tasks:**
Transformers (introduced in the 2017 paper "Attention is All You Need") revolutionized NLP by addressing core limitations of RNNs (e.g., LSTMs/GRUs). Here's a breakdown:
### 1. **Parallel Processing and Training Efficiency**
- **RNNs**: Process sequences **sequentially** (one token at a time), creating dependencies that prevent full parallelization on GPUs/TPUs. This leads to slower training, especially for long sequences (O(n) sequential steps).
- **Transformers**: Use **self-attention** to process the **entire sequence in parallel**. Computation is O(n²) but highly parallelizable, enabling massive speedups (e.g., training BERT/GPT models on huge datasets in days vs. weeks).
### 2. **Handling Long-Range Dependencies**
- **RNNs**: Suffer from **vanishing/exploding gradients**, making it hard to capture relationships between distant tokens (e.g., in long sentences or documents).
- **Transformers**: **Attention mechanisms** directly compute relationships between all pairs of tokens, regardless of distance. Positional encodings preserve order, allowing perfect modeling of long contexts (e.g., up to 128k+ tokens in modern variants like GPT-4).
### 3. **Scalability and Performance**
- **RNNs**: Scale poorly with model size/depth due to sequential bottlenecks and gradient issues; prone to overfitting on complex tasks.
- **Transformers**: Scale excellently with data, compute, and parameters (e.g., billions in LLMs). Achieve SOTA results on benchmarks like GLUE, SQuAD, machine translation (BLEU scores 2-5x better), and generation tasks.
### 4. **Flexibility and Interpretability**
- **RNNs**: Hidden states are "black boxes," hard to interpret.
- **Transformers**: Attention weights are **visualizable**, revealing what the model "focuses" on (e.g., coreferent resolution). Easier to extend (e.g., encoder-decoder for translation, pre-training like BERT).
| Aspect | RNNs (e.g., LSTM) | Transformers |
|---------------------|----------------------------|---------------------------|
| **Seq. Processing** | Sequential (slow) | Parallel (fast) |
| **Max Context** | Limited (~100-200 tokens) | Very long (100k+ tokens) |
| **Training Time** | O(n * layers * batch) | O(n² * heads * batch) |
| **SOTA NLP Use** | Legacy (pre-2018) | Dominant (BERT, GPT, T5) |
**Trade-offs**: Transformers are memory-intensive (quadratic scaling) and require more data/compute initially, but optimizations like sparse attention (Reformer), efficient transformers (Performer), or linear attention mitigate this.
In summary, Transformers' **attention-based parallelism and global context modeling** make them vastly superior for modern NLP, powering 99% of top models today. RNNs are now niche (e.g., low-resource edge devices).
========================================AI Judge Verdict
Code
print("\n>>> JUDGE'S VERDICT <<<")
print(f"MODEL_A: {MODEL_A_NAME}")
print(f"MODEL_B: {MODEL_B_NAME}")
print(f"MODEL_C: {MODEL_C_NAME}")
print(f"JUDGE: {MODEL_JUDGE_NAME}")
print("=====")
print(result['judgment'])
>>> JUDGE'S VERDICT <<<
MODEL_A: openai/gpt-oss-20b
MODEL_B: deepseek/deepseek-v3.2
MODEL_C: x-ai/grok-4.1-fast
JUDGE: google/gemini-3-flash-preview
=====
Commentary: All three models provide high-quality, accurate, and comprehensive explanations of why Transformer architectures have superseded RNNs.
Model A is the most technical and detailed, including a full table of ten distinct benefits and specific mathematical/architectural explanations (e.g., QKV vectors, matrix broadcasting, CUDA kernels). It provides the most depth for a reader looking for a rigorous understanding of the engineering advantages.
Model B is exceptionally well-structured for readability. It highlights the core concepts—self-attention and parallelization—very clearly and provides a thoughtful section on trade-offs and the remaining niche strengths of RNNs, which adds balance to the answer.
Model C is also very strong and accurate, though it slightly overstates the "interpretability" of Transformers (attention weights are often considered misleading as direct explanations) and conflates the theoretical context window of modern LLMs (like GPT-4's 128k) with the base Transformer architecture mentioned in the 2017 paper.
Model A wins due to the sheer density of relevant information and the breadth of its comparison, covering nuances like regularization techniques and modularity that the other models omitted.
Winner: Model A
Score A: 96
Score B: 90
Score C: 88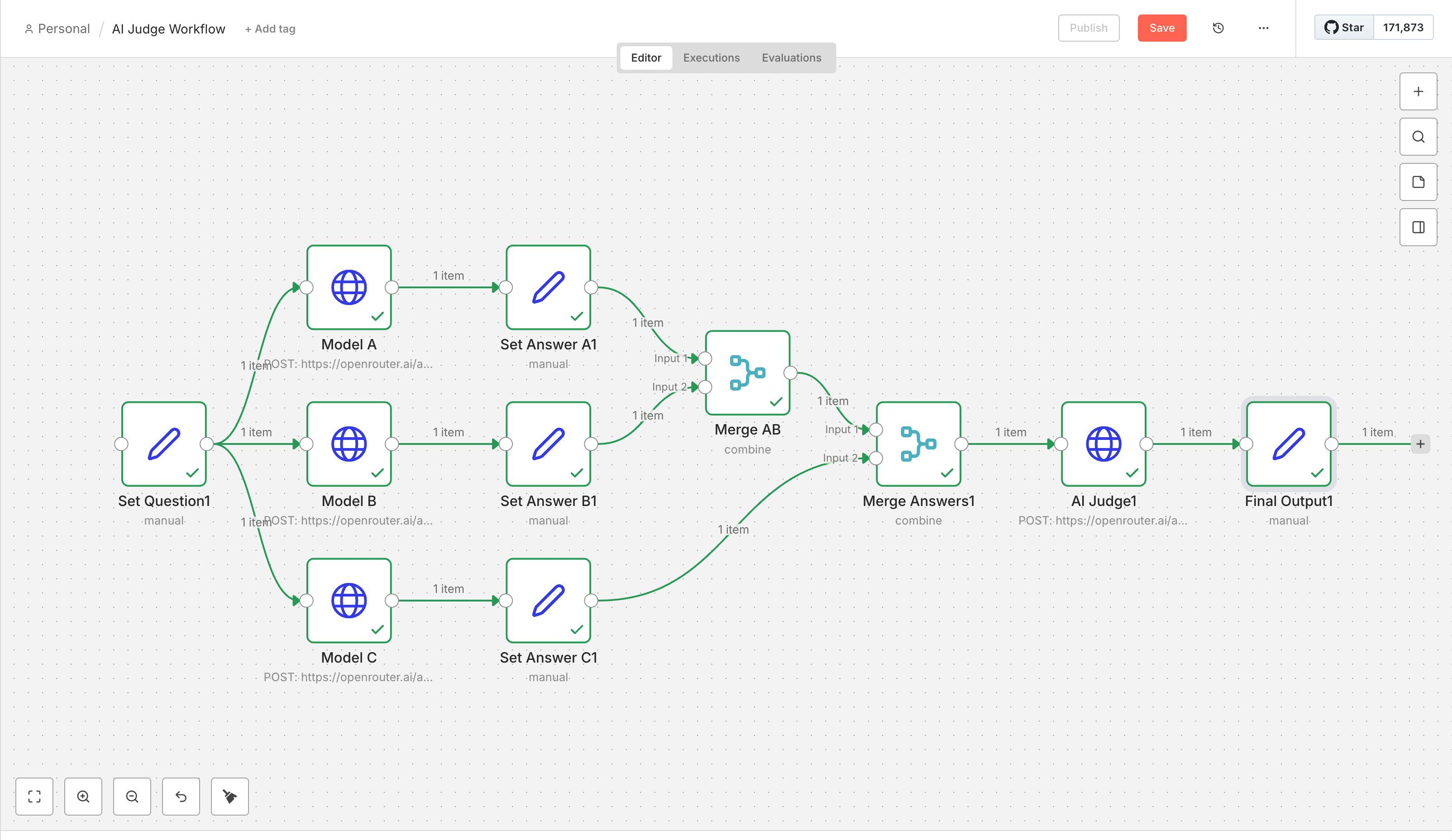
json file
Code
{
"name": "AI Judge Workflow",
"nodes": [
{
"parameters": {
"assignments": {
"assignments": [
{
"id": "question-field",
"name": "question",
"value": "what is AI?",
"type": "string"
}
]
},
"options": {}
},
"id": "30f77dc6-8e05-4ddb-8902-1638b09abe7b",
"name": "Set Question1",
"type": "n8n-nodes-base.set",
"typeVersion": 3.4,
"position": [
-688,
16
]
},
{
"parameters": {
"method": "POST",
"url": "https://openrouter.ai/api/v1/chat/completions",
"authentication": "genericCredentialType",
"genericAuthType": "httpBearerAuth",
"sendHeaders": true,
"headerParameters": {
"parameters": [
{
"name": "Content-Type",
"value": "application/json"
}
]
},
"sendBody": true,
"specifyBody": "json",
"jsonBody": "={{ JSON.stringify({\n \"model\": \"openai/gpt-oss-120b:free\",\n \"messages\": [\n {\"role\": \"system\", \"content\": \"If you do not know the answer then reply I am not sure.\"},\n {\"role\": \"user\", \"content\": $json.question}\n ]\n}) }}",
"options": {}
},
"id": "104becd7-9b3d-4297-b4ab-47b1df1abd71",
"name": "Model A",
"type": "n8n-nodes-base.httpRequest",
"typeVersion": 4.2,
"position": [
-480,
-160
],
"credentials": {
"httpHeaderAuth": {
"id": "Lf6835mjFnfNIqw6",
"name": "Header Auth account 2"
},
"httpBearerAuth": {
"id": "KFNalQ91U3mlnQks",
"name": "Bearer Auth account"
}
}
},
{
"parameters": {
"method": "POST",
"url": "https://openrouter.ai/api/v1/chat/completions",
"authentication": "genericCredentialType",
"genericAuthType": "httpBearerAuth",
"sendHeaders": true,
"headerParameters": {
"parameters": [
{
"name": "Content-Type",
"value": "application/json"
}
]
},
"sendBody": true,
"specifyBody": "json",
"jsonBody": "={{ JSON.stringify({\n \"model\": \"openai/gpt-oss-20b\",\n \"messages\": [\n {\"role\": \"system\", \"content\": \"If you do not know the answer then reply I am not sure.\"},\n {\"role\": \"user\", \"content\": $json.question}\n ]\n}) }}",
"options": {}
},
"id": "2c4d3906-bcd3-4fc6-b983-4e9e494e476f",
"name": "Model B",
"type": "n8n-nodes-base.httpRequest",
"typeVersion": 4.2,
"position": [
-480,
16
],
"credentials": {
"httpHeaderAuth": {
"id": "Lf6835mjFnfNIqw6",
"name": "Header Auth account 2"
},
"httpBearerAuth": {
"id": "KFNalQ91U3mlnQks",
"name": "Bearer Auth account"
}
}
},
{
"parameters": {
"method": "POST",
"url": "https://openrouter.ai/api/v1/chat/completions",
"authentication": "genericCredentialType",
"genericAuthType": "httpBearerAuth",
"sendHeaders": true,
"headerParameters": {
"parameters": [
{
"name": "Content-Type",
"value": "application/json"
}
]
},
"sendBody": true,
"specifyBody": "json",
"jsonBody": "={{ JSON.stringify({\n \"model\": \"arcee-ai/trinity-large-preview:free\",\n \"messages\": [\n {\"role\": \"system\", \"content\": \"If you do not know the answer then reply I am not sure.\"},\n {\"role\": \"user\", \"content\": $json.question}\n ]\n}) }}",
"options": {}
},
"id": "3f5e4a8b-c9d2-4ab7-a123-456789012345",
"name": "Model C",
"type": "n8n-nodes-base.httpRequest",
"typeVersion": 4.2,
"position": [
-480,
192
],
"credentials": {
"httpHeaderAuth": {
"id": "Lf6835mjFnfNIqw6",
"name": "Header Auth account 2"
},
"httpBearerAuth": {
"id": "KFNalQ91U3mlnQks",
"name": "Bearer Auth account"
}
}
},
{
"parameters": {
"assignments": {
"assignments": [
{
"id": "map-a",
"name": "answer_a",
"value": "={{ $json.choices[0].message.content }}",
"type": "string"
}
]
},
"options": {}
},
"id": "bb423cd5-28ff-47e5-8925-492143d26228",
"name": "Set Answer A1",
"type": "n8n-nodes-base.set",
"typeVersion": 3.4,
"position": [
-256,
-160
]
},
{
"parameters": {
"assignments": {
"assignments": [
{
"id": "map-b",
"name": "answer_b",
"value": "={{ $json.choices[0].message.content }}",
"type": "string"
}
]
},
"options": {}
},
"id": "591d8be5-132d-45a2-a69d-455467da46e5",
"name": "Set Answer B1",
"type": "n8n-nodes-base.set",
"typeVersion": 3.4,
"position": [
-256,
16
]
},
{
"parameters": {
"assignments": {
"assignments": [
{
"id": "map-c",
"name": "answer_c",
"value": "={{ $json.choices[0].message.content }}",
"type": "string"
}
]
},
"options": {}
},
"id": "7a8b9c0d-1e2f-4a3b-8c4d-5e6f7a8b9c0d",
"name": "Set Answer C1",
"type": "n8n-nodes-base.set",
"typeVersion": 3.4,
"position": [
-256,
192
]
},
{
"parameters": {
"mode": "combine",
"combineBy": "combineAll",
"options": {}
},
"id": "merge-ab-node-id",
"name": "Merge AB",
"type": "n8n-nodes-base.merge",
"typeVersion": 3,
"position": [
-32,
-72
]
},
{
"parameters": {
"mode": "combine",
"combineBy": "combineAll",
"options": {}
},
"id": "2c89b328-cac3-4322-bcf6-b8ae5f9c0af2",
"name": "Merge Answers1",
"type": "n8n-nodes-base.merge",
"typeVersion": 3,
"position": [
160,
16
]
},
{
"parameters": {
"method": "POST",
"url": "https://openrouter.ai/api/v1/chat/completions",
"authentication": "genericCredentialType",
"genericAuthType": "httpBearerAuth",
"sendHeaders": true,
"headerParameters": {
"parameters": [
{
"name": "Content-Type",
"value": "application/json"
}
]
},
"sendBody": true,
"specifyBody": "json",
"jsonBody": "={{ JSON.stringify({\n \"model\": \"google/gemini-3-flash-preview\",\n \"messages\": [\n {\n \"role\": \"user\",\n \"content\": \"You are an AI Judge. You will be presented with a question and three candidate answers (Model A, Model B, and Model C).\\nYour task is to judge the quality of the answers.\\n\\nQuestion: \" + $(\"Set Question1\").first().json.question + \"\\n\\nAnswer A:\\n\" + ($json.answer_a || \"No answer provided\") + \"\\n\\nAnswer B:\\n\" + ($json.answer_b || \"No answer provided\") + \"\\n\\nAnswer C:\\n\" + ($json.answer_c || \"No answer provided\") + \"\\n\\nTask:\\n1. Compare the three answers for accuracy, clarity, and completeness.\\n2. format and length of the answers are not important, focus on content quality.\\n3. Provide a short commentary.\\n4. Assign a score from 0 to 100 for Model A, Model B, and Model C.\\n5. Declare the overall winner.\\n\\nOutput Format:\\nCommentary: <text>\\nWinner: <Model A or Model B or Model C>\\nScore A: <number>\\nScore B: <number>\\nScore C: <number>\"\n }\n ]\n}) }}",
"options": {}
},
"id": "1d6171c9-4800-4f25-97a0-c029053e1ddc",
"name": "AI Judge1",
"type": "n8n-nodes-base.httpRequest",
"typeVersion": 4.2,
"position": [
368,
16
],
"credentials": {
"httpHeaderAuth": {
"id": "Lf6835mjFnfNIqw6",
"name": "Header Auth account 2"
},
"httpBearerAuth": {
"id": "KFNalQ91U3mlnQks",
"name": "Bearer Auth account"
}
}
},
{
"parameters": {
"assignments": {
"assignments": [
{
"id": "final-result",
"name": "verdict",
"value": "={{ $json.choices[0].message.content }}",
"type": "string"
},
{
"id": "model-a-ans",
"name": "answer_a",
"value": "={{ $node[\"Merge Answers1\"].json.answer_a }}",
"type": "string"
},
{
"id": "model-b-ans",
"name": "answer_b",
"value": "={{ $node[\"Merge Answers1\"].json.answer_b }}",
"type": "string"
},
{
"id": "model-c-ans",
"name": "answer_c",
"value": "={{ $node[\"Merge Answers1\"].json.answer_c }}",
"type": "string"
}
]
},
"options": {}
},
"id": "eae7f7bf-07fc-4250-b628-1a422cfbbe12",
"name": "Final Output1",
"type": "n8n-nodes-base.set",
"typeVersion": 3.4,
"position": [
576,
16
]
}
],
"pinData": {},
"connections": {
"Set Question1": {
"main": [
[
{
"node": "Model A",
"type": "main",
"index": 0
},
{
"node": "Model B",
"type": "main",
"index": 0
},
{
"node": "Model C",
"type": "main",
"index": 0
}
]
]
},
"Model A": {
"main": [
[
{
"node": "Set Answer A1",
"type": "main",
"index": 0
}
]
]
},
"Model B": {
"main": [
[
{
"node": "Set Answer B1",
"type": "main",
"index": 0
}
]
]
},
"Model C": {
"main": [
[
{
"node": "Set Answer C1",
"type": "main",
"index": 0
}
]
]
},
"Set Answer A1": {
"main": [
[
{
"node": "Merge AB",
"type": "main",
"index": 0
}
]
]
},
"Set Answer B1": {
"main": [
[
{
"node": "Merge AB",
"type": "main",
"index": 1
}
]
]
},
"Set Answer C1": {
"main": [
[
{
"node": "Merge Answers1",
"type": "main",
"index": 1
}
]
]
},
"Merge AB": {
"main": [
[
{
"node": "Merge Answers1",
"type": "main",
"index": 0
}
]
]
},
"Merge Answers1": {
"main": [
[
{
"node": "AI Judge1",
"type": "main",
"index": 0
}
]
]
},
"AI Judge1": {
"main": [
[
{
"node": "Final Output1",
"type": "main",
"index": 0
}
]
]
}
},
"active": false,
"settings": {
"executionOrder": "v1",
"availableInMCP": false
},
"versionId": "ac74f20b-72a9-49a6-8200-fd08707946ec",
"meta": {
"instanceId": "2f42f1cdfcab2c6a7bbd5cec68912930ccc0107686e3a7211ddcc09504c524d9"
},
"id": "8a_wyeYhdVZSr42SS5Z1K",
"tags": []
}